공간 데이터의 특별함 — 가까운 것은 먼 것보다 더 닮는다

공간 데이터는 '이웃'을 안다
보통의 데이터는 서로 남남입니다. 한 줄이 다른 줄에 대해 아무것도 알려주지 않죠. 그런데 위치가 붙는 순간, 데이터는 옆자리를 흘끔거리기 시작합니다. 가까운 것끼리 서로 닮아가는 것 — 이 단순한 성질 하나가 공간 데이터를 완전히 다른 존재로 만듭니다.
여기 시세를 전혀 모르는 아파트가 한 채 있습니다. 평수도, 연식도, 층수도 모릅니다. 딱 하나만 알려드리죠. 바로 옆 동이 얼마 전 20억에 팔렸습니다.
이제 이 집 가격을 맞혀보라고 하면, 여러분은 "한 18~22억쯤?"이라고 꽤 자신 있게 답할 겁니다. 평수도 모르면서요. '옆'이라는 단어 하나가 어떻게 이렇게 많은 걸 알려준 걸까요?
이 질문에 대한 답은, 놀랍게도 1970년에 한 지리학자가 컴퓨터 논문 한구석에 거의 농담처럼 적어둔 한 문장에서 시작됩니다.
가까운 것은 먼 것보다 더 닮는다 — 지리학 제1법칙
1970년, 지리학자 월도 토블러(Waldo Tobler) 는 디트로이트라는 도시가 어떻게 바깥으로 퍼져 나가는지를 컴퓨터로 시뮬레이션한 논문을 발표합니다. 제목부터 시대를 앞서간 「디트로이트 지역의 도시 성장을 시뮬레이션한 컴퓨터 영상」이었죠. 그는 이 모델을 굴리기 위해 세상을 단순화할 가정 하나가 필요했고, 그래서 본문에 슬쩍 이렇게 적습니다.
"모든 것은 다른 모든 것과 관련되어 있다. 다만 가까운 것이 먼 것보다 더 관련되어 있다." (everything is related to everything else, but near things are more related than distant things.)
본인은 그저 모델을 돌리기 위한 임시방편으로 던진 한 줄이었습니다. 그런데 이 문장은 훗날 공간과학에서 가장 많이 인용되는 한 줄이 되어 '지리학 제1법칙(First Law of Geography)'이라는 거창한 이름까지 얻습니다. 각주가 법칙이 된 셈이죠.
법칙이라기엔 너무 당연해 보이나요? "가까우면 비슷하다"는 건 누구나 아는 상식이니까요. 옆 동네 날씨가 지구 반대편 날씨보다 우리 동네랑 비슷하고, 부잣집 옆엔 부잣집이 있고, 사투리는 지역끼리 닮습니다.
하지만 이 '당연한 상식'이 법칙으로 격상된 데에는 이유가 있습니다. 이게 사실은, 우리가 학교에서 배운 통계의 가장 기본적인 전제를 정면으로 들이받기 때문입니다.
왜 '법칙'씩이나 되는가 — 통계의 대전제가 무너진다
우리가 아는 거의 모든 통계는 한 가지 약속 위에 서 있습니다. 바로 표본은 서로 독립이라는 약속입니다.
동전을 던질 때, 방금 앞면이 나왔다고 다음번 결과가 달라지지 않습니다. 설문조사에서 A씨의 답이 B씨의 답에 영향을 주지도 않죠. 데이터들이 서로 남남이기 때문에, 우리는 평균을 내고 p-value를 계산하고 "유의미하다"고 말할 수 있습니다. 이 독립이라는 전제가 통계라는 건물의 주춧돌입니다.
그런데 공간 데이터는 이 전제를 체계적으로, 그것도 대놓고 깹니다.
서울 한 지점의 기온을 알면, 옆 동네 기온은 안 봐도 거의 압니다. 한 아파트 가격을 알면 옆 동 가격이 보이고요. 한 점의 값이 이웃을 보면 상당 부분 예측된다면, 그 둘은 더 이상 독립이 아닙니다. 동전 던지기로 치면, 방금 앞면이 나온 동전 옆 동전도 앞면일 확률이 높은 이상한 세계인 거죠.
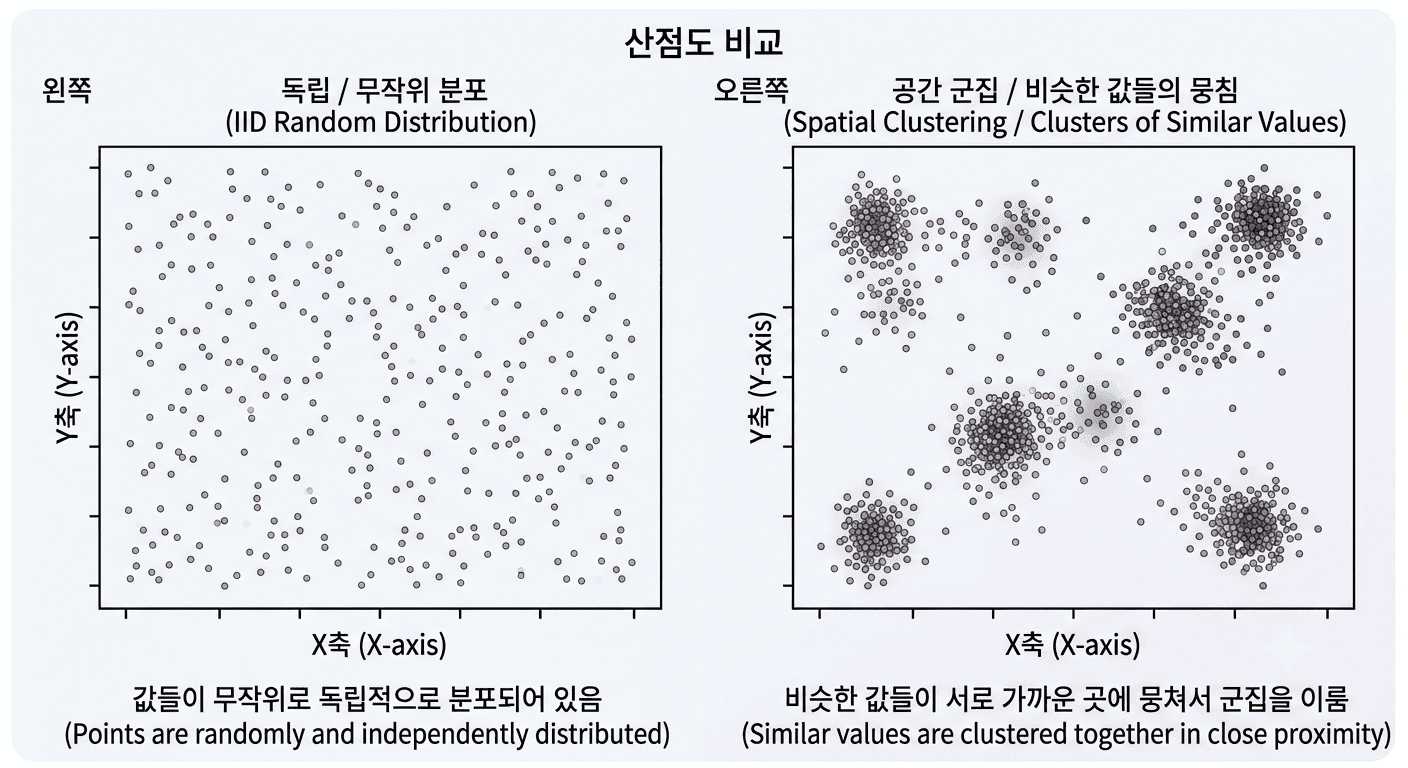
그래서 토블러의 한 줄이 법칙인 겁니다. 단순한 상식이 아니라, "공간 데이터에는 일반 통계를 그냥 쓰면 안 된다" 는 경고이자, 동시에 "이웃을 보면 미래가 보인다" 는 무기 선언이거든요.
💡 이 '이웃끼리 닮는 정도'는 데이터마다 다릅니다. 어떤 데이터는 끈끈하게 뭉치고, 어떤 데이터는 거의 무작위죠. 그렇다면 이 닮음을 숫자 하나로 잴 수 있다면 편하지 않을까요? 실제로 그런 도구가 있습니다. (그 이야기는 곧 아래에서.)
이름을 붙이면 — 공간적 자기상관
이 "가까운 것끼리 값이 닮는 현상"에는 정식 이름이 있습니다. 바로 공간적 자기상관(spatial autocorrelation) 입니다. 말이 어렵지, 뜻은 우리가 이미 본 그대로예요. "이웃한 위치끼리 값이 얼마나 닮아 있는가".
이 닮음은 세 가지 얼굴을 가집니다.
- 양의 자기상관 — 비슷한 값끼리 뭉칩니다. 부촌 옆 부촌, 고온 지역 옆 고온 지역. 현실의 공간 데이터 대부분이 여기에 속합니다. (집값, 소득, 미세먼지 농도…)
- 음의 자기상관 — 오히려 서로 밀어냅니다. 체스판처럼 다른 값이 번갈아 나오죠. 경쟁 점포가 일부러 거리를 두고 깔리거나, 나무들이 햇빛을 두고 일정 간격을 유지하는 경우.
- 자기상관 없음 — 그냥 무작위. 어디에 무엇이 있든 이웃과 아무 상관이 없습니다.

앞에서 "이 닮음을 숫자 하나로 잴 수 있다면" 했던 것 기억나죠? 그 대표 도구가 Moran's I라는 지표입니다. 데이터가 양으로 뭉쳤는지(+1에 가까움), 음으로 흩어졌는지(−1에 가까움), 아니면 무작위인지(0 근처)를 단 하나의 숫자로 요약해 주죠. 지금은 "공간의 뭉침 정도를 측정하는 자가 따로 있다"는 것만 기억해 두면 충분합니다. 실제 계산은 시리즈의 공간 분석·통계 편에서 본격적으로 다룰 거예요.
용어 하나만 챙겨 갑시다. 공간적 자기상관 — 이 단어가 앞으로 공간 데이터를 이해하는 열쇠가 됩니다.
1854년, 그 점들이 뭉쳐 있던 이유
사실 우리는 이 시리즈에서 공간적 자기상관을 이미 한 번 목격했습니다.
GIS란 무엇인가 편에 나온 1854년 런던, 의사 존 스노우의 콜레라 지도를 떠올려 보세요. 사망자가 발생한 집을 하나하나 점으로 찍었더니, 그 점들이 브로드 스트리트 펌프 주변으로 빽빽하게 뭉쳐 있었죠.

그 '뭉침'이 바로 양의 공간적 자기상관입니다. 사망자라는 사건이 무작위로 흩어진 게 아니라, 특정 위치 주변에 끈끈하게 모여 있었던 것. 만약 콜레라가 정말 '나쁜 공기' 때문이었다면 점들은 동네 전체에 고르게 퍼졌어야 합니다. 하지만 점들은 한 곳을 가리키고 있었죠.
스노우는 '지리학 제1법칙'도, '자기상관'이라는 단어도 몰랐습니다. 존 스노우가 한 일은 그저 공간이 보여주는 패턴을 믿은 것뿐입니다. 가까운 죽음들은 우연이 아니라 같은 원인을 공유한다 — 토블러보다 116년 앞서, 이미 공간 데이터의 본질을 읽어내고 있었던 겁니다.
🔗 GIS란 무엇인가 편에서는 스노우의 이야기를 'GIS적 사고의 원형'으로 봤습니다. 이번엔 같은 이야기를 한 겹 더 들어가, 왜 그 방법이 통했는지를 봅니다. 답은 공간 데이터가 독립이 아니기 때문, 즉 점들이 뭉쳐 있었기 때문입니다.
축복이자 저주
공간 데이터가 독립이 아니라는 이 성질은, 양날의 검입니다.
축복 — 빈 곳을 채울 수 있다. 이웃이 서로 닮는다면, 측정하지 않은 지점의 값도 주변을 보고 추정할 수 있습니다. 미세먼지 측정소는 전국에 듬성듬성 박혀 있지만, 우리는 매끄러운 전국 미세먼지 지도를 봅니다. 측정소 사이의 빈 공간을 이웃 값으로 메운(보간한) 결과죠. 일기예보, 부동산 추정가, 강수량 지도가 전부 이 축복 위에서 돌아갑니다. "가까운 것은 닮는다"가 곧 "안 본 곳도 맞힐 수 있다" 가 되는 겁니다.
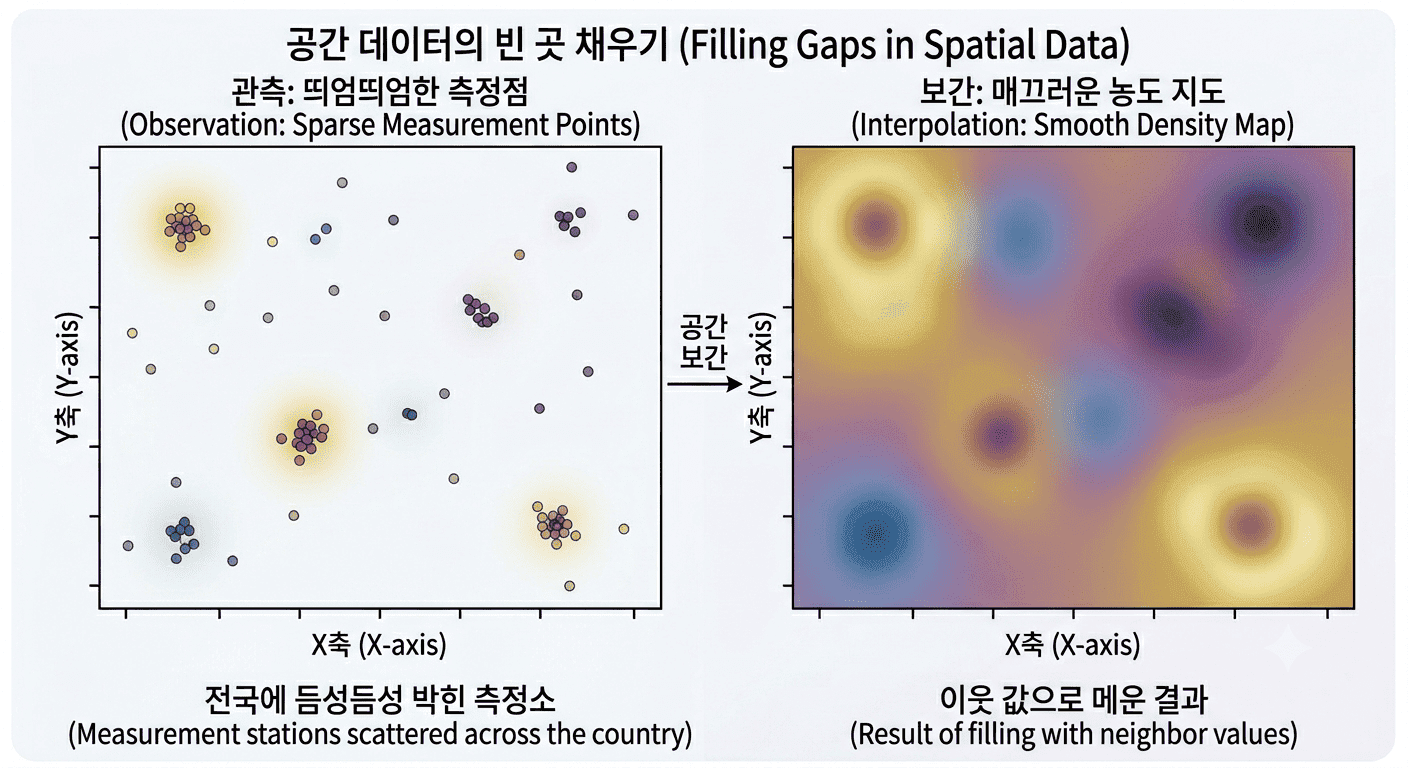
저주 — 통계가 거짓말을 한다. 같은 이유로, 공간 데이터를 일반 통계 도구에 그냥 집어넣으면 엉뚱한 결론이 나옵니다. 독립이라는 전제가 깨졌으니까요. 예를 들어 "치킨집이 많은 동네일수록 범죄가 많다"는 그럴듯한 상관이 나와도, 사실은 둘 다 그냥 사람 많은 도심에 몰려 있을 뿐일 수 있습니다. 공간은 이렇게 있지도 않은 인과를 만들어내는 함정을 곳곳에 깔아둡니다. 그래서 공간 데이터를 다루는 사람은 늘 "이거 진짜 관계야, 아니면 그냥 둘 다 가까이 있는 거야?"를 의심해야 하죠.
축복을 누리려면, 저주를 알아야 합니다. 그리고 이 둘을 제대로 다루려면 — 일반적인 도구로는 부족합니다.
그래서 공간 데이터는 '따로' 다룬다
이제 이 시리즈 전체를 관통하는 이유에 도착했습니다.
엑셀과 일반 데이터베이스, 일반 통계 패키지로 세상 대부분의 데이터를 다룰 수 있습니다. 그런데 왜 유독 공간 데이터에는 전용 포맷(GeoJSON, Shapefile…), 전용 데이터베이스(PostGIS), 전용 인덱스(R-tree, H3), 전용 분석 기법이 따로 존재할까요?
답은 지금까지 본 단 한 가지 성질 때문입니다. 공간 데이터는 독립이 아니다 — 가까운 것은 더 닮는다. 이 하나의 사실이,
- "반경 500m 안의 가게"를 빠르게 찾으려면 → 일반 인덱스론 안 되니 공간 인덱스가 필요하고,
- "이 권역 안에 저 점이 들어가나"를 따지려면 → 공간 연산을 아는 데이터베이스가 필요하고,
- 측정 안 한 곳을 추정하거나 군집을 찾으려면 → 공간을 아는 분석 기법이 필요하게
만듭니다. 앞으로 우리가 다룰 좌표계, 데이터 포맷, 공간 DB, 타일, 렌더링 — 그 거의 전부가 결국 "공간은 다르다"는 이 한 문장의 후속편입니다.
정리 — 한 문장으로
공간 데이터의 본질은 '독립이 아니라는 것'이다. 가까운 것은 먼 것보다 더 닮고, 그래서 따로 다뤄야 한다.
| 개념 | 한 줄 정의 | 일상 예 |
|---|---|---|
| 지리학 제1법칙 | 가까울수록 더 닮는다 | 옆 동네 날씨가 더 비슷하다 |
| 공간적 자기상관 | 이웃끼리 값이 닮는 정도 | 집값·소득·미세먼지의 군집 |
| 축복 | 빈 곳을 이웃으로 채워 예측 | 측정 안 한 곳의 농도 추정 |
| 저주 | 독립 가정이 깨짐 | 거짓 상관·틀린 통계 |
옆 동이 20억에 팔렸다는 말 한마디로 이 집 시세를 맞힐 수 있었던 이유, 이제 보이시죠? 그건 우리가 무의식적으로 지리학 제1법칙을 쓰고 있었기 때문입니다. 공간 데이터는 늘 이웃을 흘끔거리고, 그래서 우리는 안 본 것도 어림짐작할 수 있는 겁니다.